嘉宾介绍
邓德源 才云科技CTO
美国卡内基梅隆大学硕士,专修操作系统、分布式计算等方向。前谷歌集群管理组核心成员,参与开发了谷歌所有运维工程师的统一集群管理入口,后者为谷歌自动化运维的重要组成部分。在谷歌期间作为核心成员参与了Kubernetes设计、开发和实现,自动化管理谷歌近百个数据中心中的上百万台服务器和每周20亿个容器化应用等项目。
一、谷歌技术管理部分方法实践
技术项目管理的宏观理论很多,而我在本次分享中以我在谷歌从事软件开发和技术项目管理的角度,介绍一下我们采用的一些具体的、细化的实践方法和工具。由于Google内部系统庞大,不同的团队在不同的时间会采取不同的方案,我这里只列举一些常用的方法实践:
A 、SRE, Interrupts与release shepherd
谷歌内部非常注重开发与运维的分离;对于传统的运维我们定义为手动的、重复性的、没有长久附加价值的人工劳动。因为,谷歌内部鼓励通过Devops的方法逐渐减少传统运维的成分。例如谷歌内部采用自动化的集群管理平台(基于容器技术和容器集群管理平台Borg等工具),使得一名运维人员(与传统运维人员不同,谷歌内部称之为Site Reliability Engineering)平均可以管理上万台服务器。谷歌具体的开发与运维分离方法包含两种:
(1)将开发者(SWE:Software Engineer)与运维者(或者谷歌特色的SRE: Site Reliability Engineer)分岗,SRE转岗负责更多的平台级别的维护。同时,即使在SRE岗位内部,谷歌也严格控制每名SRE所参与的手动运维时间,尽量将其控制在50%一下,保证SRE能有一半的时间投身于自动化运维工具、系统、平台的研发。当然,SRE也有oncall,当接收到紧急任务时(被传呼),当值的SRE需要在10多分钟内到达键盘前做出响应。
(2)在开发者中也不可避免的从事一些运维或者处理应用突发事件的时候。例如当某个线上服务出现问题时,SRE往往会找到对应的开发团队协助调查原因并提交修复补丁。为了减少此类突发事件对于开发人员的研发任务影响,不少开发团队采用interrupts轮岗制:在每一个产品版本发布周期内,轮流由一名开发者来担当interrupts角色,并与SRE团队协调,成为SRE的point of contact,负责处理外来interruption和bug的初步诊断(triage)。
B 此外,谷歌的产品新版本上线有着严格的QA和测试流程,除了和大家所熟悉的开发、测试、生产环境的搭配使用以外,想突出两个特点:
(1)谷歌的产品测试不依赖于专门的测试工程师,而是要求软件作者自己要去进行一系列的单元、整合测试,以及在测试环境的测试等。软件作者在极大程度上是自己代码的负责人。
(2)在新版本的发布过程中,我们深度采用了不同形式的灰度测试机制。例如如果是平台软件更新(例如容器集群平台,服务器基础镜像升级),是按照一定的速度逐渐更新到不同的数据中心,例如第一天发布到一个数据中心,第二天发布到5个数据中心,以此类推,并在过程中不断进行A/B测试和对比。如果是面向用户的产品(例如广告、购物等),则会采用基于用户流量分流的灰度发布法,例如先选择5%的用户流量使用新的版本,并自动收集metrics来进行新、旧版本的比对。
二、谷歌DevOps理念与实践分享
时间关系,这次分享中我仅介绍一些高层的Devops理念。首先,软件工程的过程就像生一个小孩,而维护这个出生后的软件往往在谷歌内部要花费40%到90%的精力。传统的运维存在诸多问题,例如较高的人力成本,对运维人员的长期职业发展不利,以及造成开发团队和运维团队之间的利益冲突。而谷歌内部的Devops实践被称为Site Reliabiliy Engineering,是希望将大部分的人工运维时间转化为开发自动化运维工具的时间,从而从长远来讲实现更高程度的自动化系统管理。而SRE的最重要的目标就是稳定性。
SRE体现了如下的核心智慧:
一定要专注于持久的运维工具开发,将人工操作降到50%的时间以下。
采用error budget(错误预算)的方式来缓解开发团队与SRE团队(或运维团队)之间的利益冲突:开发团队希望新的版本迭代越快越好,而运维团队希望系统越稳定越不变越好。
在设定SLO的时候,不应该力求100%的稳定性,而是根据系统所有环节,制定N个9。
系统一定要有稳健的监测系统,四个黄金监测对象包括:延迟、流量、错误率和资源饱和率。
系统中的70%的问题都是由于配置改变所导致的,所以配置管理是核心要素。
敏捷的持续集成和持续发布系统是必须,包括构建、切分支、测试、打包几个部分。
采用容器技术和自动化容器集群管理技术是实现高可用、高效能系统的秘密武器。
三、谷歌DevOps的常用工具
首先大家应该都听说过容器是什么,而Docker则是基于容器技术的现阶段最流行的一种容器产品、工具和生态。对于不了解Docker或者容器的人,一个简单的比喻(但不是最贴切)就是容器就是一个更轻量级的“虚拟化”和“应用隔离”工具。具体有多轻量呢?一个服务器可能可以运行10个虚拟机,但是一个服务器上可以运行上百个容器,不同容器里运行用户的应用,并在一定程度上实现了相互之间的隔离。此外,容器可以在秒级启动,相比于启动一个完整的虚拟机也有巨大的优势。除了效能上的提升,容器还是一种应用的打包格式,可以将应用和它运行时的依赖封装在一起,实现一次封装、处处运行的功能。
谷歌从2000年初开始使用容器,但是它所使用的是自研的一种叫做lmctfy的容器格式,其实是Let Me Contain That For You几个单词首字母的缩写。谷歌最早使用容器的初衷之一是节省物理资源,通过用容器取代虚拟化层(hypervisor和每个虚拟机所占用的物理资源)来极大地节省计算成本。谷歌在2013年对lmctfy其进行了开源https://github.com/google/lmctfy,但由于流行程度不如Docker,后面就没有再继续推广。同时,根据谷歌内部运行15年容器的经验来看,将应用程序装入容器仅仅是第一步,而后面的大量工作是如何管理、运维这一个全新的容器世界,因此谷歌在2014年将精力转入了开源容器集群管理技术,即Kubernetes项目:https://github.com/kubernetes/kubernetes
四、谷歌容器集群技术实践分享
下面我们正好来聊聊谷歌容器集群的实践。谷歌在2015年已经达到了80多个数据中心,超过一百万台机器。其中大家所熟知的search,youtube,maps,gmail等所有产品,包括很多我们使用的内部工具,都是基于容器在运行。这个容器的数量是巨大的,官方称之为每周运行20亿个容器。那么紧接着我们面临的问题就是如何去管理这么多的容器,其包括:
决定哪个容器运行在哪台服务器上
如何实现应用容器的多副本部署来实现高可用、高并发,同时按需动态伸缩以节省、优化资源利用率
如何自动监测应用的运行状况,并在出错误时进行自我修复和故障转移
如何实现应用于配置的解耦合,使得一个数据中心的业务系统可以快速的“全盘”复制到另外的数据中心里(我们称之为cluster turnup and turndown,基本上是每个季度都会发生的事情)
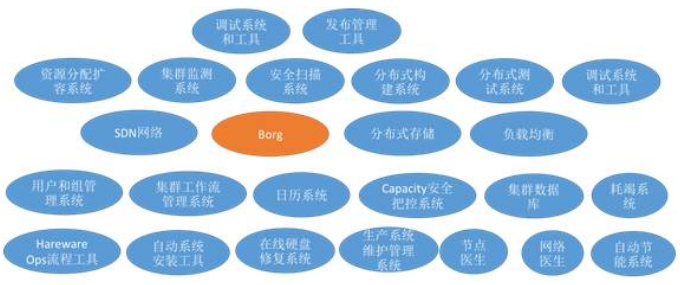
谷歌为此建立了一整套集群管理(Cluster Management)机制,其中包含几十种不同的组建。如下图所示:
其中在外界知名度最高的容器任务管理组件:Borg。它之所以在外界更为人所熟知,一方面是由于谷歌发表了关于Borg的论文:《Large-scale cluster management at Google with Borg》, 另一方面也由于谷歌基于Borg的思想和实践开源了Kubenretes项目。Borg的最主要功能是一个容器任务调度和编排系统,负责将容器化应用自动地运行在何时的主机上,并对容器应用的生命周期(生老病死)进行自动化优化管理。下面我通过一个案例来描述一下这一整套集群管理系统的实践流程。我们以建立一个新的数据中心并在其上运行一套广告业务为例来看看谷歌的一整套运维、开发、管理流程。
1、初始化
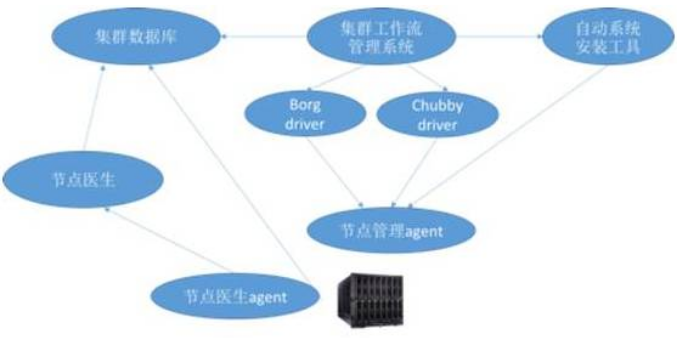
我们从硬件开始说起。当一台服务器从QA通过后,它会投放到数据中心里的一个合适的rack中。当硬件设施、网络都配好后,该服务器的信息会被写入一个集中的机器数据库里。这个数据库里不光记录了机器的硬件配置信息,还会记录这台服务器会被赋予哪些平台级别的特殊使命(例如运行Borg的master节点、运行Chubby服务器等)。默认地,每一个服务器上都要运行Borg的工作节点服务(Borglet),用来运行用户应用和业务。
随后,在集群管理系统里一个叫做“亚里士多德”的组件会定期(每15分钟)获取机器数据库中的最新数据,当发现有新的服务器时,则会按照指示对该服务器进行配置:
a) 先通过调用一个叫做installer的组件对机器进行操作系统的安装(谷歌叫做Prodimage,是一个基于Ubuntu的经过安全改良的系统镜像)
b) 然后根据数据库中的指示,在服务器上安装合适的平台软件(borglet,borgmaster,chubby等)。
这里指的点出的是,我们对于每一个生产服务器的配置和安装,并非是通过ssh进行,而是通过在机器上安装一个API服务(称为sushiD),并通过调用API进行。这样可以避免SSH所暴露出来的过多的权限和潜在的attack surface。这个流程我用图表总结如下:
2、管理和监测系统平台
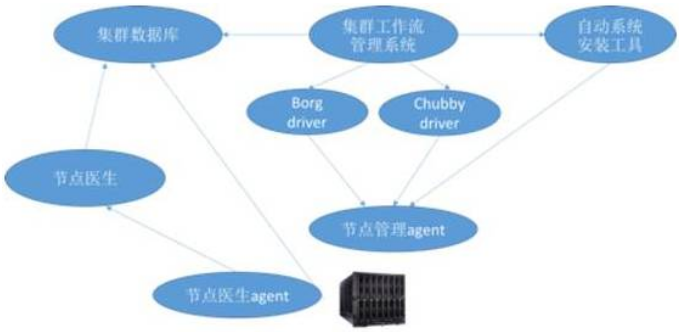
当服务器和平台服务都运行起来以后,集群管理系统则处于一个有限状态机的模式,对服务器和上面的平台软件(例如Borg,Chubby等)进行不间断、自动化的管理和维护。
每个机器上安装的一个“机器医生”agent会时刻关注服务器状态(例如通过观测/proc目录等),并根据自己的一个“症状规则库”判断机器是否出现问题,例如 bad-hda, slow-ethernet等,如有,则将此问题加入机器数据库中。
亚里士多德系统在定期检查机器数据库时会发现服务器上的问题,并采用相应的workflow和工具进行软件修复。在谷歌,有60%的“硬盘”或文件系统故障都可以通过此自动化在线修复工具完成修复,无需人工介入。
除了对机器的管理,亚里士多德还会通过预先定义的server 模块和健康检查机制检查平台软件的健康性(例如Borg等)。无论是出现软件问题,还是软件所在的机器出现了问题,根据策略我们会采取不同的修复手段和软件迁移机制。例如如果是Borg的master所在的物理服务器出现硬件问题,哪怕这个问题还没有影响到上面的服务(例如机器过热),亚里士多德会触发在线替换的workflow,主动在新的机器上部署Borg Master服务,做到未雨绸缪。
当修复机器问题时,我们要做的一个准备工作叫做drain,就是把机器上的业务和数据先删除掉(由于谷歌内部的应用、数据都采用分布式结构,使得删除某个节点不会影响整体业务)。然而在删除前,亚里士多德系统会询问一些安全把控组件,保证该服务器下线后不会影响整体的系统容量。
上述是一个非常基本的工作流,只是管中窥豹。我用流程图总结如下:
3、发布并运行应用
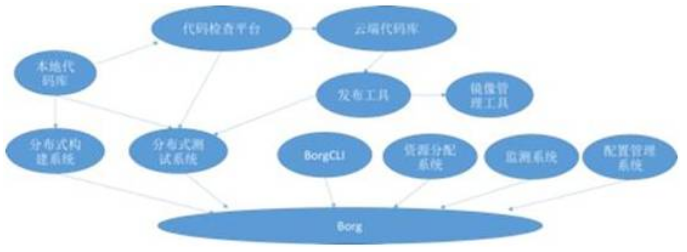
谷歌的代码都存放在同一个庞大的代码库中,开发者在开发完代码后类似于Github里的Pull Request一样也要发一个Change List,进行code review。在谷歌,code review是严格执行的,否则代码无法提交(除了特殊情况)。大致的开发流程如下:
1)开发者写好代码后,先在本地进行编译。由于谷歌的代码库非常庞大,编译代码所需的依赖可能就需要很长时间。谷歌内部使用了一个叫做blaze的编译和测试工具,Blaze可以运行在Borg容器集群上,通过优化的依赖分析,高级的缓存机制,和并行的构建方法,可以快速地对代码进行构建。而谷歌也将这一工具进行开源:http://www.bazel.io/
2)构建完成后,我们需要在本地进行单元测试,而单元测试的运行测试由一个内部叫做Forge的系统完成,而Forge也是通过运行在Borg容器集群上从而实现快速的并行测试。
3)当本地的代码更新以Change List的形式发送出来以后,谷歌内部的人员通过一个叫做Critique的UI进行代码审查,同时Change List会触发一个叫做TAP(Tap Anything Protocol)的系统对该Change List进行单元测试,并保证这个局部的代码变化不会影响谷歌的其他应用和代码。TAP具有智能的依赖监测功能,会在谷歌内部浩瀚的代码库和产品线中检测到哪些部分可能会被潜在的影响到。
4)当代码通过测试和审核提交后,我们会等到下一个release cycle进行发布。如前所述,谷歌内部的应用都是以容器的形式运行在Borg上。因此发布的第一步工作就是通过一个叫做Rapid的系统,对代码进行容器打包成镜像(内部称为MPM格式),再通过Rapid发布工具进行发布(按照前述的灰度发布原则)。
用流程图总结如下:
4、应用运行期间的自动化管理
最后,我来简单分享下谷歌是如何采用容器集群Borg来实现其应用的高可用和高扩展性的。由于Borg博大精深,我这里只列举一些经典的功能:
1)动态任务调度:开发者通过Borg的命令行来将应用跑起来。在一个Borg Cell里,Borg调度器将会动态的、自动的、智能的为不同的应用选择合适的机器来运行。如大数据业务、cron job、Google web业务、搜索业务等应用都会被动态的分配到集群中的不同主机上,调度算法会根据每个主机当前的物理资源情况来做优化,实现物理资源利用率最大化,并保证各个主机的流量平均分配,不会造成局部热点。不同的任务有不同的优先级,来保证大数据任务不会在用户流量高峰期抢占web业务的资源。
2)模块、服务间的自动服务发现:Borg内运行的所有应用都有一个类似于DNS的名称,我们内部称之为BNS Path。不同的服务间相互访问时可以直接根据BNS名称来进行连接,BNS系统会自动地将名称转化为实际的IP地址。因此,在不同的环境切换时(例如从测试到生产)、或随着主机的重启或更换而导致底层IP地址变化,应用程序也无需做任何修改就可做到无缝迁移,极大地减少了环境配置和人工操作来带的成本与风险。此外,BNS的方式也更好地支持了应用的多实例部署,在具体的实例发生变化时,应用的BNS不变。
3)多副本负载均衡与弹性伸缩:为了应对互联网应用的突发和难以预测的用户流量,用户在Borg平台部署应用时可指定所需要的副本数量,例如运行10个Nginx的实例。Borg会自动创建指定个数的应用实例,并且:
a) 对应用进行实时监测,保证任何时候都有指定数量的实例在运行。如果由于主机故障导致2个Nginx实例失效,Borg会主动地创建2个新的Nginx实例来保证高可用。
b) 当其他服务需要访问Nginx时,无需直接绑定具体10个实例中的任何一个IP地址,而是可以通过上述的服务名称(例如“Nginx”)来访问。Borg会自动将请求按照一定的负载均衡策略转发到10个实例中的合适实例。
c) 集群管理中的其他组件如 Autoscaler还支持自动伸缩策略,例如当CPU利用率超过60%时,自动将Nginx从10个实例扩展到20个实例。
4)自我修复与故障应对:当应用程序出现故障时,Borg会自动发现并在新的主机上重启应用。Borg检测故障的方法可以针对业务和应用进行定制化,除了简单地检测应用是否在运行以外,还支持基于HTTP钩子的自定义监测(内部称为healthz和varz)。而其开源的Kubernetes也支持类似的自定义健康检查规则:
a) HTTP钩子:例如对于Web应用,检测其服务URL是否正常
b) 检测脚本:对于任意应用,通过定时在应用容器中运行自定义脚本进行检测。以Redis为例,可以通过 “redis-cli”来进行自定义的数据检查。
c) TCP socket:可以通过检测TCP socket来判断应用是否健康。
5)配置管理:一个复杂的生产系统中存在诸多配置,除了不同组件的IP地址、端口,还有应用程序的配置文件、中间件的配置文件等。Borg充分利用了基于Chubby的配置管理服务,实现应用与配置的分离。用户可以将不同环境下的应用配置文件、数据库密码、环境变量等配置放入每个集群内统一的Chubby服务中,并为每一个配置项取名字(例如 “APP_CONFIG_FILE”, “DB_PASSWORD”等),而后应用可通过这些名字来在运行时获取这些与环境相关的配置信息。此外,Chubby支持watcher功能,因此应用程序可以动态监听其配置文件是否有变化,实现配置的热更新。感兴趣的朋友可以参考Chubby的论文来了解更多详情:http://research.google.com/archive/chubby.html
五、才云DevOps落地实践
前面提到的都是来自 Google 的经验,最后我们简单介绍一下 Caicloud 的实践。我们在内部也尝试去做到 devops;实践过程中,发现最难的地方其实并不在于工具的研发、使用和推广;最困难的地方还是在于如何完善整个 devops 的流程、如何培养工程师养成 devops 的思维方式。因此,我们从一开始就需要引导工程师,让其成为平台的利益相关者。这里,主要提一下代码管理、持续交付、运维开发:
(1) 版本控制软件
显然,现在软件开发都采用版本控制;这里,我们主要强调如何管理分支、如何有效的提交代码、如何使用 semver (http://semver.org/) 等,防止管理混乱。另外,我们有严格的代码审查要求,所有提交都需要有 peer review,reviewer 需要理解代码的内容、检查逻辑错误,还需要思考一个问题“如果是自己提交该功能要如何实现”。公司目前整体执行较好,前端开发由于迭代速度等问题很难完全达到要求。但是,前端至少需要在每个提交需要提供一个本地的服务,reviewer 可以通过内网访问到带有新代码逻辑的 UI 界面,从而更好的理解代码逻辑、发现程序 bug。
(2) 持续交付
持续交付由专门的团队负责,负责在公司内推广持续集成、持续部署。我们采用 kubernetes 作为容器平台,并自研了持续交付的平台 https://github.com/caicloud/cyclone。目前我们已经在公司内使用了 cyclone 平台,具体细节可以参考项目本身。后续计划添加更多功能,包括更好的配置管理、部署方案、流水线管理等。
(3) 运维开发
我们发现要真正实践 SRE 的准则在现阶段是非常困难的。运维基本很难要求有很强的开发能力,开发也不了解运维的场景。我们目前的运维团队组成包括开发转运维工程师、开发和传统运维。其中运维开发工程师负责协调组内任务及关键开发任务;开发和传统运维紧密合作完成开发及运维任务:运维负责传统的运维,开发收集运维的信息,包括调试、调优、事故处理等等,然后进行自动化开发。例如,我们将 hadoop 运行在 kubernetes 上,编写类似于 kubernetes controller manager 的模块,负责管理 hadoop 在 kubernetes 上运行的生命周期。此类模块在专职开发和传统运维之间的配合下逐渐成熟。目前我们的很多自动化运维的功能都是基于规则的,长期来看,我们也在思考使用机器学习的可能性。
精彩问答
Q1:老师分享的机器医生是否能够发现所有的硬件故障,能否具体说说实现原理?
A1:能发现大部分,原理就是采集本地proc,sys下的各种指标,然后通过内部的规则和机器学习来检测问题。机器医生是个主从结构,有一个机器医生 master,将所有机器上的 report 给关联起来,检测错误。比如某个数据中心过热,或者某片网络挂了等。如果某个地区的节点医生都在汇报问题,那 master 可以认为这个地区出现了问题而不是个别的问题。硬件问题都是从 os report 来的,至于具体的规则库和算法都是私密的。
Q2:老师您好,我想请问一下,一个做日常IT/服务器运维的职场新人,如何转向DevOps方向?除了一门编程语言之外,能给出具体的技术栈吗?
A2:运维去转 devops 的话,编程一定花心思学,要在学中用,编程能力的提升是个制约转 devops 的关键。
Q3:再具体一点的话,编程能力大概要什么水平才能算DevOps的入门水平呢?懂一点点前端,可以自己独立的写一套简单的运维系统(前后端,集成Zabbix)够不够呢?DevOps的招聘更加倾向于传统运维人员还是开发?
A3:很难有个具体的指标,现在我们的一个做法就是说能手动运维去操作的东西,能通过编程的方式表达出来。
(本文于2016-12-05首次发布)